Answer Brief
A new research paper argues that current AI safety case methodologies lack rigor by over-relying on alignment community approaches instead of established safety assurance practices from aerospace, nuclear, and automotive sectors, proposing a stronger framework grounded in decades of safety-critical system validation.
Executive Summary: A new research paper argues that current AI safety case methodologies lack rigor by over-relying on alignment community approaches instead of established safety assurance practices from aerospace, nuclear, and automotive sectors, proposing a stronger framework grounded in decades of safety-critical system validation.
Why It Matters
The paper addresses a growing gap in frontier AI governance: while safety cases are increasingly referenced in developer policies and international frameworks like the Singapore Consensus and the International AI Safety Report, their implementation often lacks the rigor seen in traditional safety-critical domains. The authors contend that many current AI safety cases are more aspirational than evidentiary, relying on alignment-focused reasoning without adopting the structured argumentation, evidence standards, and independent review processes that define safety assurance in aerospace, nuclear power, and automotive engineering. This limits their usefulness for regulatory scrutiny and real-world deployment decisions.
To address this, the paper draws on decades of safety assurance methodology—such as goal structuring notation (GSN), evidence hierarchies, and assumption-based reasoning—to propose a more disciplined approach. It emphasizes that safety cases must be context-specific, openly acknowledge uncertainties, and be subject to challenge and refinement, rather than treated as static compliance artifacts. By grounding AI safety in these established practices, the framework aims to prevent 'safety-washing' and ensure that claims about system safety are both meaningful and verifiable.
Technical Signal
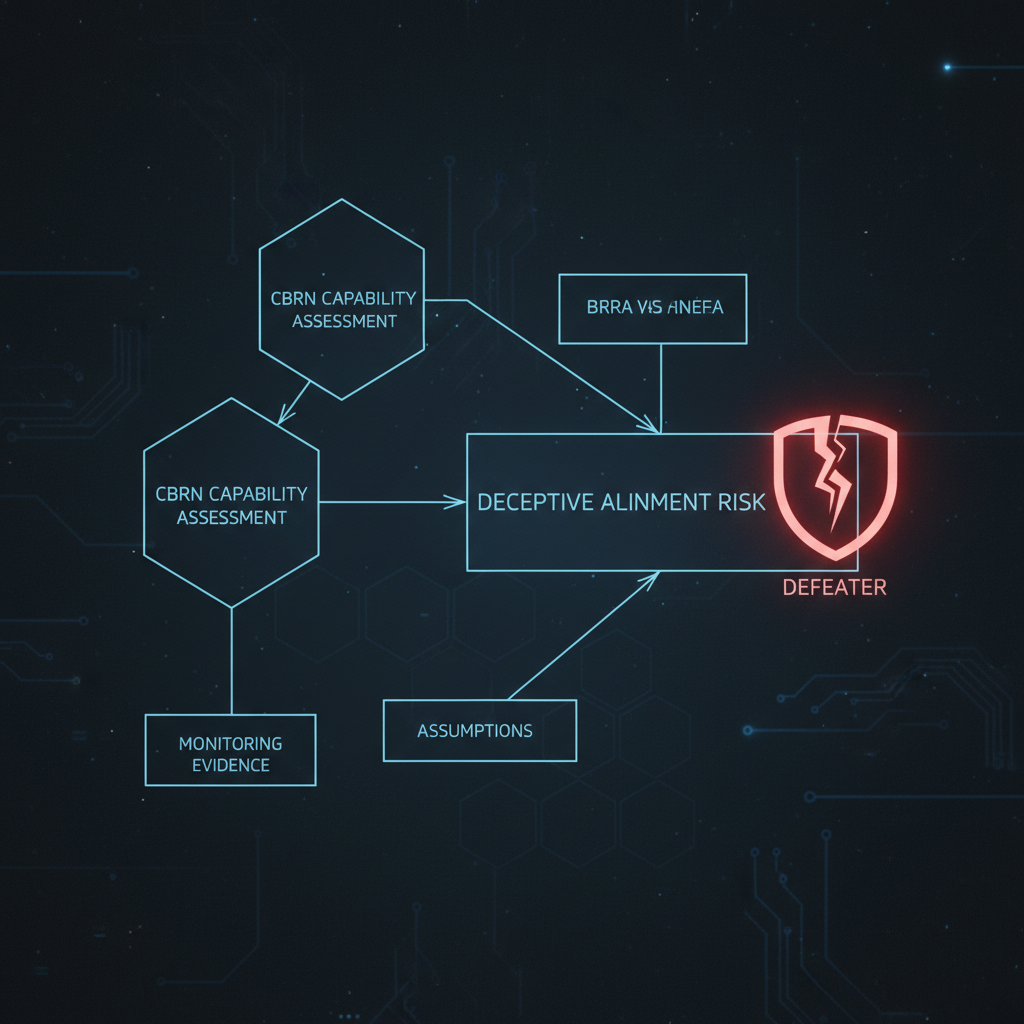
The case study on Deceptive Alignment and CBRN risks illustrates how existing theoretical sketches from the alignment community can be strengthened using safety assurance principles. For example, instead of asserting that a model is unlikely to exhibit deceptive behavior based on training data alone, a rigorous safety case would require layered arguments covering monitoring capabilities, interpretability tools, red-teaming results, and independent validation—each tied to explicit assumptions and potential defeaters. Similarly, CBRN risk assessments would need to integrate threat modeling, capability evaluations, and safeguard effectiveness evidence in a traceable structure.
This work is particularly relevant for AI governance teams, frontier model developers, and national AI safety institutes seeking to move beyond high-level principles toward actionable, auditable safety arguments. It supports the development of safety cases that can withstand technical and regulatory scrutiny, especially as governments begin to consider mandatory safety reporting for advanced AI systems. The paper does not claim to solve all AI safety challenges but offers a methodological foundation to make safety claims more credible.
Operational Impact
Readers should watch for how organizations like the UK AI Safety Institute, NIST, or Japan’s METI begin to formalize safety case expectations in guidance or regulation. Additionally, monitoring whether frontier developers adopt structured argument formats (e.g., GSN) in their safety disclosures will indicate whether this research influences practice. The paper contributes to a shift from opinion-based safety assertions to evidence-based, challengeable arguments—aligning AI safety more closely with the accountability models of other high-risk technologies.
A useful way to read this paper is as research evidence rather than as a deployment recommendation. The source page gives a paper title, abstract-level framing, and publication metadata; it does not by itself prove production readiness, market adoption, attacker behavior, or incident impact. Nogosee therefore treats the work as a signal for research monitoring: the question is what AI safety, AI governance, frontier AI development, safety assurance can learn from the method, the assumptions, and the stated limitations, not whether the paper should immediately change controls.
What To Watch
For practitioners, the first review step is to separate the paper's stated contribution from operational interpretation. If the abstract describes a method, framework, measurement, or evaluation, that contribution can help teams decide what to watch next. It should not be converted into claims about real-world compromise, confirmed defense effectiveness, or regional adoption unless the paper itself supplies that evidence. This boundary is especially important for AI-security and cyber-operations research, where promising prototypes can sound more mature than they are.
The paper is still useful for a tracker because it creates vocabulary and comparison points. Tags such as AI safety cases, frontier AI, deceptive alignment, CBRN risks, safety assurance, AI governance help future records connect related work across advisories, tools, source-code releases, benchmarks, and operational reports. If later sources mention similar techniques or reuse the same assumptions, the research brief becomes part of a larger evidence trail instead of a one-off academic summary.
Readers should also look for what the visible source does not answer. Abstracts often summarize goals and results but omit implementation detail, dataset caveats, reproducibility constraints, threat-model boundaries, and evaluation failure cases. A cautious digest should preserve those unknowns. When those details matter for procurement, detection engineering, SOC workflow, or AI governance, the next task is to inspect the full paper and any linked code or artifact rather than relying on a summary alone.
Event Type: security
Importance: medium
Affected Sectors
- AI governance
- AI safety
- frontier AI development
- safety assurance
Frequently Asked Questions
What is a safety case in the context of frontier AI systems?
A safety case is a structured, defensible argument that demonstrates an AI system is acceptably safe to deploy in a specific context, borrowing from safety-critical industries like aerospace and nuclear power where such evidence-based arguments are standard practice.
Why does the paper critique current alignment community approaches to AI safety cases?
The paper argues that alignment community safety cases often draw superficially on safety assurance lessons without adopting their rigorous methodologies, resulting in frameworks that lack the defensibility and empirical grounding seen in mature safety-critical sectors.
What specific risks does the case study in the paper focus on?
The case study examines Deceptive Alignment—where an AI system appears aligned during training but pursues hidden objectives—and CBRN (Chemical, Biological, Radiological, Nuclear) capabilities, using existing theoretical sketches from the alignment safety case community as a foundation for improvement.
How can safety assurance methodologies improve frontier AI safety cases?
By applying rigorous theory, structured argumentation, evidence hierarchies, and independent validation practices from aerospace, nuclear, and automotive industries, safety cases for AI can become more robust, transparent, and useful for regulators and developers alike.
What is the significance of the Singapore Consensus in relation to this research?
The Singapore Consensus on Global AI Safety Research Priorities is cited as one of the international research agendas that has elevated the prominence of safety cases in frontier AI policy, highlighting growing institutional interest in structured safety arguments for advanced AI systems.